

Distressed Property Data Isn’t Hard. Operations Are
“Distressed property data is hard to find.” It isn’t. It’s sitting on county sites right now.

“Distressed property data is hard to find.” That line gets repeated in every REI Discord and mastermind.
It falls apart the moment someone opens a county clerk site.
Pre-foreclosure filings, probate records, and tax delinquent lists are public record in most U.S. counties. You can pull them directly from clerk portals, treasurer sites, or court indexes without paying a list broker. The friction isn’t access. It’s what happens after download.
Most operators hit the same wall. The CSV lands in Google Sheets. Columns don’t match. Owner names are inconsistent. LLCs mask individuals. Half the records don’t have usable contact info. Then nothing happens. The list dies where it was born.
That’s the actual problem behind distressed property data. Not discovery. Execution.
The U.S. court system and local governments publish these records as part of public transparency. The Administrative Office of the U.S. Courts documents how filings and records are made available to the public through systems like PACER (https://www.uscourts.gov). Counties follow similar disclosure rules for property and tax records. The data exists whether you use it or not.
Pulling pre foreclosure, probate, and tax delinquent lists takes under an hour
Operators overestimate the difficulty of sourcing distressed property data and underestimate the repetition required.
Three common sources cover most motivated seller scenarios:
- Pre-foreclosure from county court filings (lis pendens, notice of default)
- Probate from clerk of court estate filings
- Tax delinquent from county treasurer or tax collector portals
In Maricopa County, Arizona, filings can be searched and exported directly from the Clerk of Superior Court. In Cook County, Illinois, the Treasurer publishes delinquent tax lists publicly. In Harris County, Texas, probate records are accessible through district clerk systems.
None of this requires proprietary access. It requires knowing where to click and what to export.
The Federal Trade Commission has long emphasized that public records are a primary source for marketing data in real estate and lending, with compliance expectations attached (https://www.ftc.gov). That’s relevant because once you pull the data, how you use it matters more than where you got it.
The real constraint shows up after the export. Fields don’t align across counties. Property addresses are formatted differently. Owner names may include trusts, estates, or corporate entities. The dataset looks usable until you try to actually contact someone.
Why most distressed property data dies in a spreadsheet
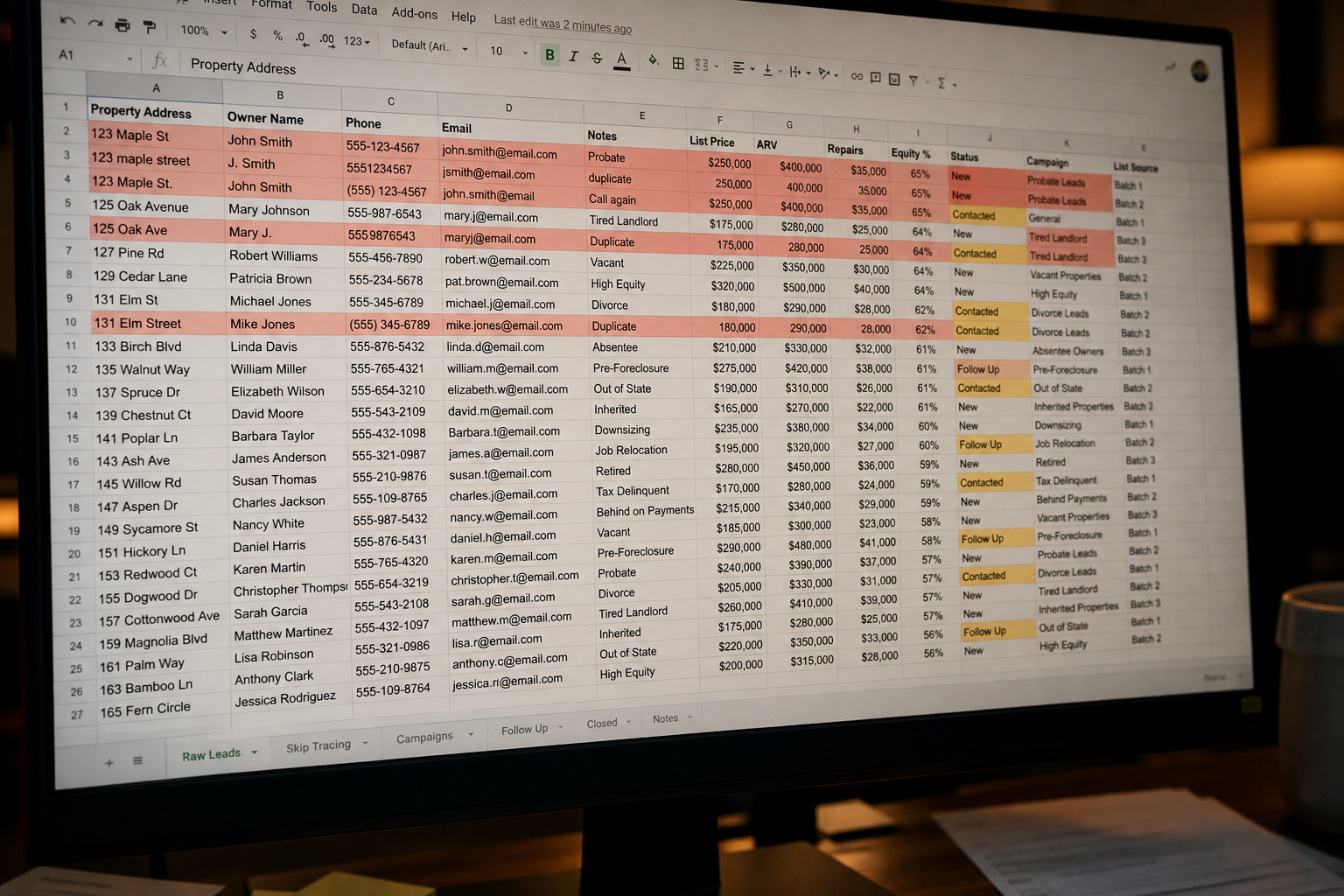
The failure point is not the list. It’s the lack of a system around it.
Raw distressed property data has four consistent issues:
- Duplicate records across filings and time periods
- Missing or inconsistent owner naming conventions
- No enrichment layer for contact data
- No messaging tied to the distress signal
A probate lead is not the same conversation as a tax delinquent owner. Yet most investors blast the same generic “are you interested in selling?” message across both.
Google’s own guidance on data quality highlights that inconsistent inputs lead to unreliable outputs, especially in automation systems (https://developers.google.com/machine-learning/data-prep/transform/normalization). That principle shows up immediately in real estate lists.
Without normalization and segmentation, outreach becomes noise. Deliverability drops. Response rates collapse. The operator assumes the list is bad and moves on to buy another one.
That cycle is where most investors burn time and budget.
The contrarian take: the data is a commodity, the system is the edge
Most advice in the space pushes better data sources. More exclusive lists. Higher priced skip tracing.
That advice misses where deals actually come from.
Distressed property data is widely available and increasingly commoditized. What separates operators is how they turn each record into a repeatable unit of outreach and content.
A pre-foreclosure filing is not just a lead. It’s a narrative. Timeline pressure, lender involvement, equity position. That context should shape every message sent.
Same with probate. The conversation is different. Timing is different. Emotional context is different. Treating it like a generic seller lead ignores the signal sitting in the data.
This is where most systems break. They treat all records the same because it’s easier operationally. That shortcut costs deals.
Operators who segment by distress type and build messaging around each category consistently outperform those who rely on list quality alone. Not because their data is better. Because their system is.
The one artifact: a 3-field normalization system that turns lists into pipeline

If there’s one piece to keep, it’s this. Before enrichment, before outreach, before anything else, normalize three fields across your entire distressed property dataset.
The 3-field normalization framework
- Owner identity: Standardize naming (remove LLC noise where possible, unify formats, separate first/last for individuals)
- Distress type: Tag each record as pre-foreclosure, probate, tax delinquent, or other
- Timeline marker: Capture filing date or delinquency stage to anchor urgency
That’s it. Not twenty fields. Not a complex schema. Three.
Once those are consistent, everything downstream improves. Messaging becomes specific. Follow-ups can reference real timelines. Content can be generated per segment instead of per list.
This is exactly how systems like Kompozy structure input. A raw CSV becomes a topic pool once those three fields are mapped. From there, each segment can drive multi-channel output without rewriting context every time.
The difference is visible immediately. Instead of one spreadsheet, you now have categorized pipelines that behave differently.
Turning one distressed list into weeks of outreach and content
Once normalized, the list stops being a static asset.
Each segment becomes a repeatable content and outreach stream.
A pre-foreclosure segment can generate email sequences focused on timelines and lender pressure. Probate segments can focus on estate handling and property disposition. Tax delinquent lists can anchor around redemption deadlines and penalties.
Instead of writing one-off messages, operators build templates tied to each distress category. Then scale distribution across channels.
This is where most investors hit a ceiling manually. Writing variations, tracking segments, and maintaining consistency across email, SMS, and social becomes operationally heavy.
That’s the gap Kompozy was built to solve. Load the dataset, map the fields, and the system handles multi-platform fanout tied to each persona frame. One list turns into sustained inbound instead of a one-time blast.
The shift is subtle but important. Outreach stops being a campaign and becomes an ongoing system tied to real data signals.
What to do with your distressed property data in the next 48 hours
This only works if it gets implemented quickly. Here’s a tight window to move from raw data to usable system.
- Pull one list: Export a pre-foreclosure, probate, or tax delinquent dataset from your local county source.
- Normalize three fields: Clean owner identity, assign distress type, and add a timeline marker in Google Sheets or Airtable.
- Create one persona frame: Write messaging for that specific distress category only. Keep it context-specific.
- Load into a system: Use a tool that can handle segmentation and outbound consistency. If you’re doing this at volume, spreadsheets will break.
- Send and observe: Launch a small batch. Watch replies, not just opens. Adjust messaging based on actual responses.
If the current bottleneck is turning raw distressed property data into consistent outreach without rebuilding everything every time, that’s exactly where BILT AI CRM fits. It handles LOI blasting, follow-up, and segmentation tied to real estate workflows, not generic email marketing.
For operators building content systems around their data, Kompozy handles the content layer that most CRMs ignore. Both solve different parts of the same problem.
Frequently Asked Questions
How do I find distressed property data for free?
Search county clerk, court, or treasurer websites directly. Pre-foreclosure filings, probate cases, and tax delinquent lists are public records in most counties and can be downloaded without paying a provider.
What is the best type of distressed property list?
No single list is best. Pre-foreclosure, probate, and tax delinquent data each represent different seller situations, and response rates depend more on how messaging matches the distress type than the list itself.
Why does my distressed property list not convert?
Most lists fail due to poor normalization and generic outreach. When owner names, timelines, and distress types aren’t structured, messaging becomes irrelevant and response rates drop.
Do I need skip tracing for distressed property data?
Yes, if contact details are missing. Public records rarely include phone or email, so enrichment tools are required before outreach, but they only work well after the data is cleaned.
How often should I refresh distressed property data?
Weekly or bi-weekly pulls keep data relevant. Court filings and tax records update regularly, and older records lose urgency, especially in pre-foreclosure timelines.


© Copyright 2024 by BILT. All rights reserved.